Pixel Transformer: Challenging Locality Bias in Vision Models
The deep learning revolution in computer vision has shifted from manually crafted features to data-driven approaches, highlighting the potential of reducing feature biases. This paradigm shift aims to create more versatile systems that excel across various vision tasks. While the Transformer architecture has demonstrated effectiveness across different data modalities, it still retains some inductive biases. Vision Transformer (ViT) reduces spatial hierarchy but maintains translation equivariance and locality through patch projection and position embeddings. The challenge lies in eliminating these remaining inductive biases to further improve model performance and versatility.
Previous attempts to address locality in vision architectures have been limited. Most modern vision architectures, including those aimed at simplifying inductive biases, still maintain locality in their design. Even pre-deep learning visual features like SIFT and HOG used local descriptors. Efforts to remove locality in ConvNets, such as replacing spatial convolutional filters with 1×1 filters, resulted in performance degradation. Other approaches like iGPT and Perceiver explored pixel-level processing but faced efficiency challenges or fell short in performance compared to simpler methods.
Researchers from FAIR, Meta AI and the University of Amsterdam challenge the conventional belief that locality is a fundamental inductive bias for vision tasks. They find that by treating individual pixels as tokens for the Transformer and using learned position embeddings, removing locality inductive biases leads to better performance than conventional approaches like ViT. They name this approach “Pixel Transformer” (PiT) and demonstrate its effectiveness across various tasks, including supervised classification, self-supervised learning, and image generation with diffusion models. Interestingly, PiT outperforms baselines equipped with locality inductive biases. However, the researchers acknowledge that while locality may not be necessary, it is still useful for practical considerations like computational efficiency. This study delivers a compelling message that locality is not an indispensable inductive bias for model design.
PiT closely follows the standard Transformer encoder architecture, processing an unordered set of pixels from the input image with learnable position embeddings. The input sequence is mapped to a sequence of representations through multiple layers of Self-Attention and MLP blocks. Each pixel is projected into a high-dimensional vector via a linear projection layer, and a learnable [cls] token is appended to the sequence. Content-agnostic position embeddings are learned for each position. This design removes the locality inductive bias and makes PiT permutation equivariant at the pixel level.
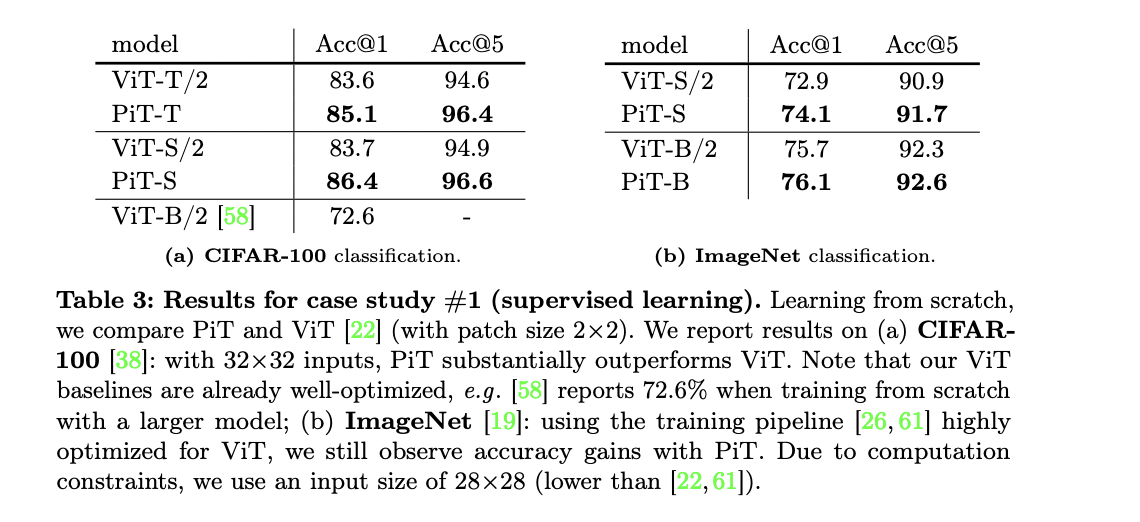
In empirical evaluations, PiT demonstrates competitive performance across various tasks. For image generation using diffusion models, PiT-L outperforms the baseline DiT-L/2 on multiple metrics, including FID, sFID, and IS. The effectiveness of PiT generalizes well across different tasks, architectures, and operating representations. Also the results on CIFAR100 with 32×32 inputs, PiT substantially outperforms ViT. Researchers found that for PiT, self-supervised pre-training with MAE improves accuracy compared to training from scratch. The gap between ViT and PiT, with pre-training, gets larger when moving from Tiny to Small models. This suggests PiT can potentially scale better than ViT.
While PiT demonstrates that Transformers can directly work with individual pixels as tokens, practical limitations remain due to computational complexity. Nonetheless, this exploration challenges the notion that locality is fundamental for vision models and suggests that patchification is primarily a useful heuristic trading efficiency for accuracy. This finding opens new avenues for designing next-generation models in computer vision and beyond, potentially leading to more versatile and scalable architectures that rely less on manually inducted priors and more on data-driven, learnable alternatives.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.