
NACL: A Robust KV Cache Eviction Framework for Efficient Long-Text Processing in LLMs
Large Language Models (LLMs) with extended context windows have shown remarkable potential in handling complex tasks such as long conversations, document summarization, and code debugging. However, their deployment faces significant challenges, primarily due to the enormous memory consumption of the KV Cache mechanism. This issue is particularly pronounced in fixed-memory hardware environments. For example, a 7 billion-parameter model with a modest input batch size and sequence length can require 64GB of KV cache, far exceeding the memory needed for the model weights themselves. This memory bottleneck severely limits the practical application of LLMs in resource-constrained settings.
Researchers have developed various methods to address KV cache memory challenges in LLMs. Approaches like H2O and Scissorhands explore sparsity in Transformer attention blocks to evict unnecessary tokens. Other techniques include learnable token selection mechanisms and modifications to attention structures. Efficient Transformers aim to reduce self-attention complexity using techniques like dilated sliding windows or combined attention types. Length extrapolation research focuses on adapting positional embeddings for extended context windows. However, the effectiveness of these methods in real-world long-context tasks may be overestimated when evaluated solely using metrics like perplexity.
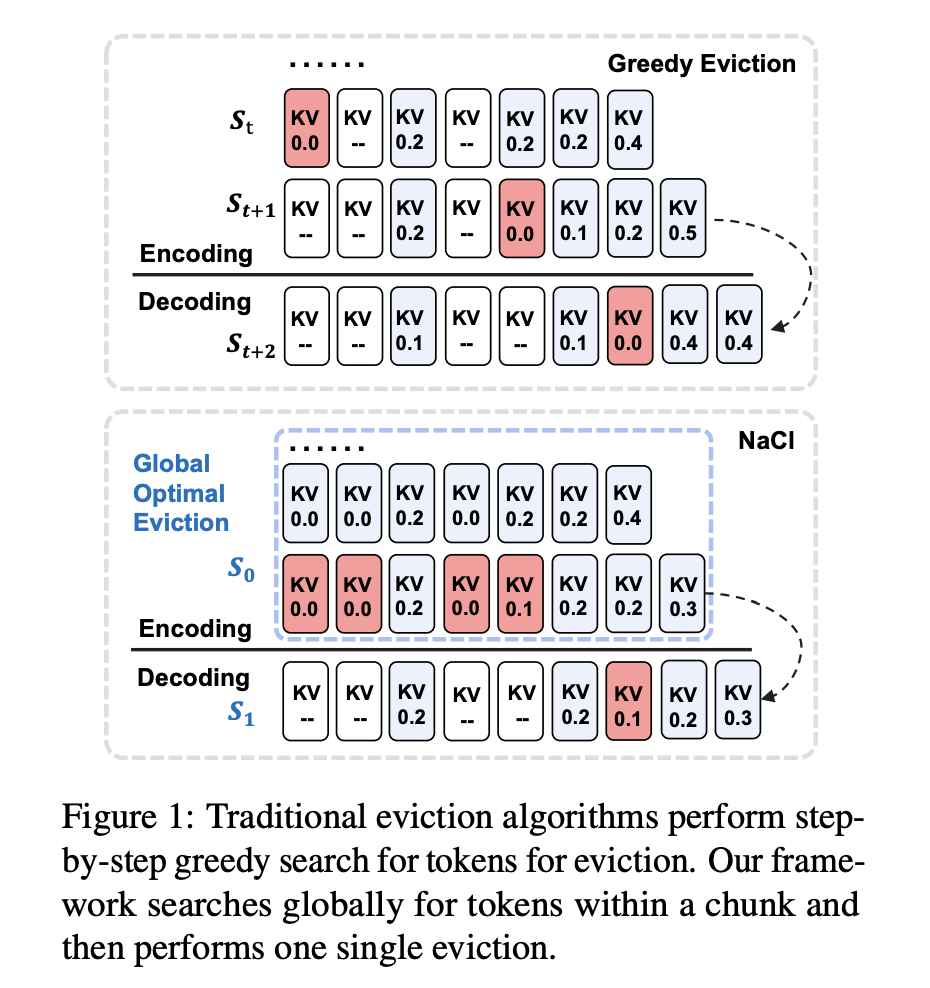
Researchers from the Institute of Information Engineering, Chinese Academy of Sciences, School of Cyber Security, University of Chinese Academy of Sciences, and Baidu Inc. introduce NACL a unique KV cache eviction framework for LLMs, focusing on the encoding phase rather than generation. It implements a one-time eviction process across the entire input, progressively clearing KV caches layer by layer. The key feature, PROXY-TOKENS EVICTION, uses global statistics from task-relevant proxy tokens, typically found in question inputs at the end of long texts. This approach overcomes attention bias problems seen in methods using local statistics or irrelevant proxy tokens. NACL aims to enhance long-context modeling performance while efficiently managing memory constraints in LLMs.
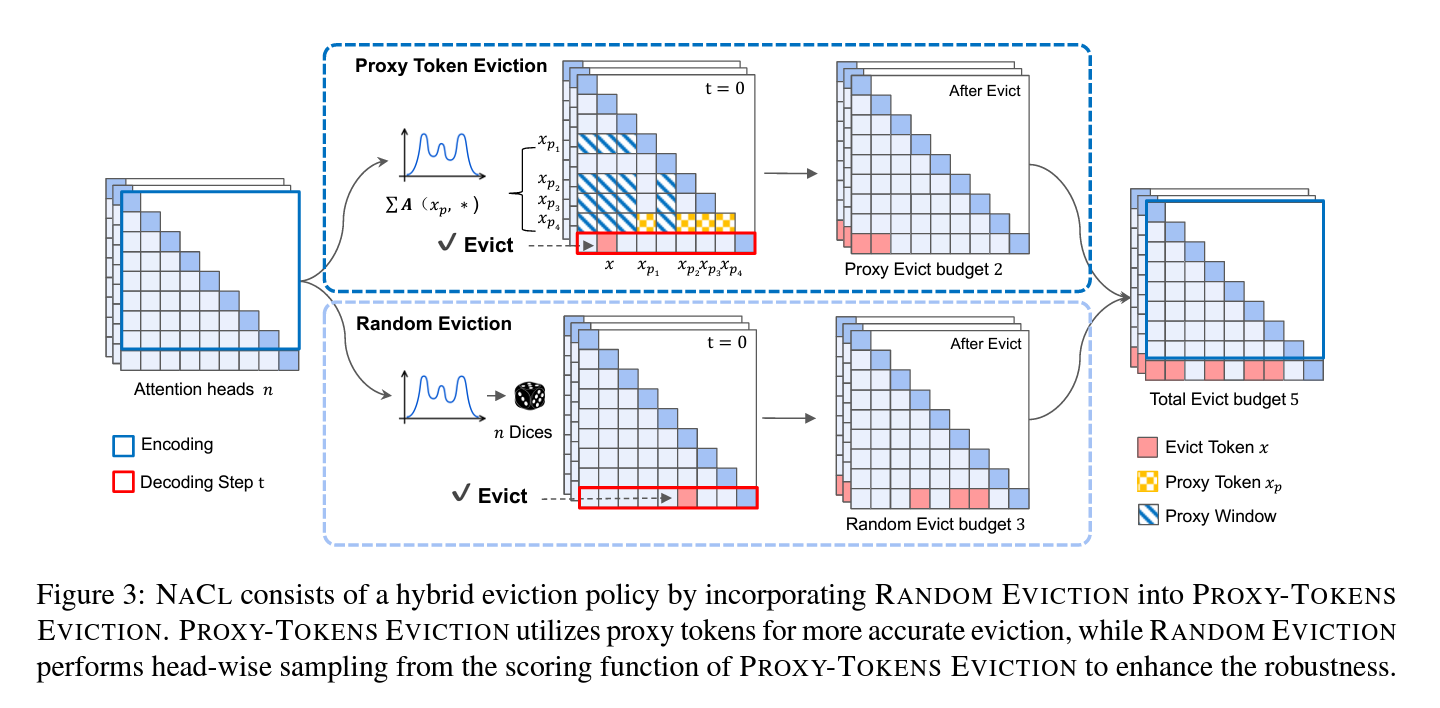
NACL introduces a hybrid KV cache eviction policy combining PROXY-TOKENS EVICTION and RANDOM EVICTION.
PROXY-TOKENS EVICTION identifies a subset of proxy tokens within the input that accurately estimates token importance. The scoring function aggregates attention scores from these proxy tokens, reducing bias and improving eviction quality. This method optimizes token retention while satisfying cache budget constraints.
RANDOM EVICTION incorporates randomness into the eviction process to enhance robustness. It constructs a probability distribution based on token significance and randomly samples from it. This approach helps preserve essential information that might otherwise be lost due to attention biases.
NACL combines these methods, applying an efficient one-eviction strategy under a total KV cache budget. The hybrid approach balances accurate token importance estimation with randomness to improve performance in long-text tasks. The method is compatible with efficient attention mechanisms like FlashAttention-2, minimizing memory and computational overhead for deployment in resource-constrained environments.

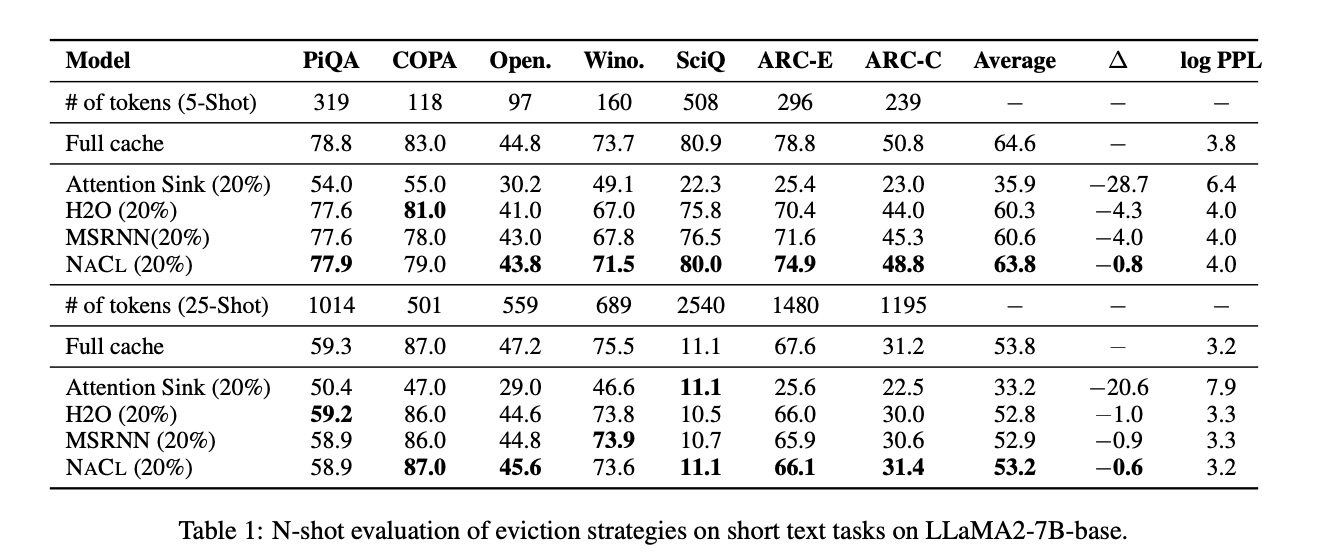
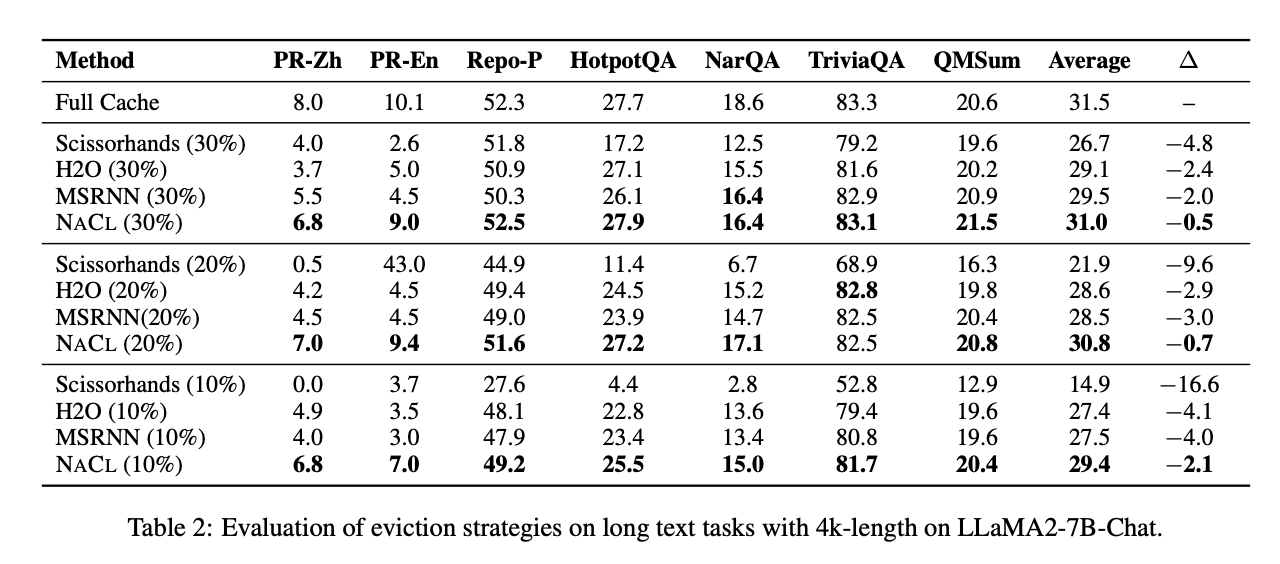
NACL demonstrates impressive performance in both short-text and long-text scenarios while managing the KV cache under constrained memory budgets. In short-text benchmarks, NACL nearly matches full cache performance, achieving an average score of 63.8% in 5-shot settings compared to the full cache’s 64.6%. It significantly outperforms H2O by 3.5 percentage points. Even in more complex 25-shot settings, NACL shows resilience, maintaining performance levels close to or matching full cache setups in some datasets. For long-text tasks, NACL achieves an 80% memory usage reduction with only a 0.7 percentage point decrease in average accuracy. It can achieve 3x more reduction in KV cache while maintaining comparable performance to baselines. NACL shows stable performance across different budget settings, even surpassing full cache performance in some tasks like HotpotQA and QMSum.
NACL’s effectiveness is particularly evident in retaining pivotal information in long inputs, outperforming methods like H2O and MSRNN that suffer from attention bias. This demonstrates NACL’s robust ability to process complex long texts while efficiently managing memory constraints.
The research introduces NACL, a robust KV cache eviction algorithm for LLMs processing long texts. NACL combines PROXY-TOKENS EVICTION and RANDOM EVICTION, reducing memory usage during inference without additional training. The approach models eviction as a combinatorial optimization problem, using importance-based references and composite sampling. Extensive evaluation shows NACL significantly improves cache eviction strategies, reduces inference memory costs, and minimizes impact on LLM task performance. This research contributes to optimizing LLM efficiency, potentially enabling longer text processing with fewer computational resources. Future work may explore further refinements and broader applications of NACL.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.








