
Can LLMs Visualize Graphics? Assessing Symbolic Program Understanding in AI
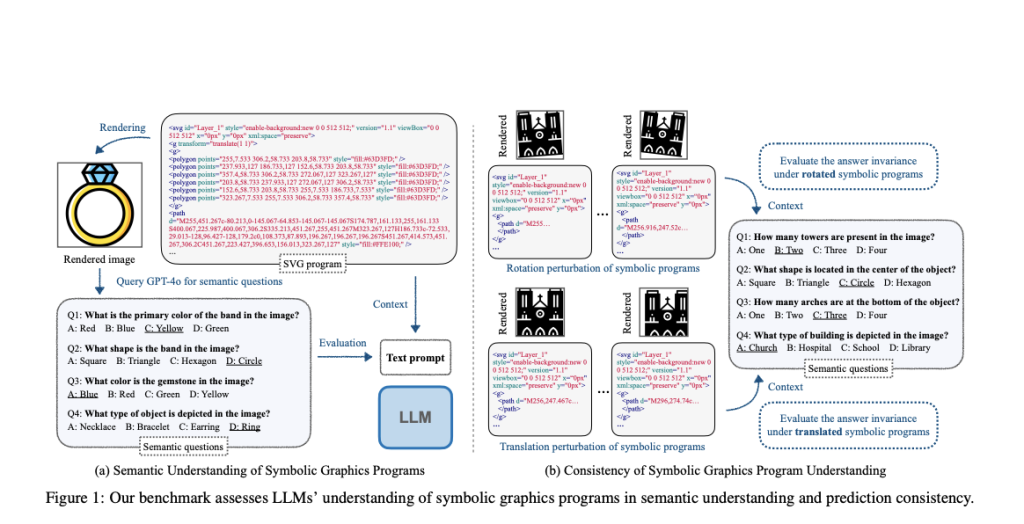
Large language models (LLMs) have demonstrated the ability to generate generic computer programs, providing an understanding of program structure. However, it is challenging to find the true capabilities of LLMs, especially in finding tasks they did not see during training. It is crucial to find whether LLMs can truly “understand” the symbolic graphics programs, which generate visual content when executed. They define this understanding as the ability to understand the semantic content of the rendered image based only on the raw text input, of the program. This method involves answering questions about the image’s content without actually viewing it, which is easy with visual input but much harder when relying only on the program’s text.
Existing research on symbolic graphics programs has primarily focused on procedural modeling for 2D shapes and 3D geometry. These programs, such as Constructive Solid Geometry (CSG), Computer-Aided Design (CAD), and Scalable Vector Graphics (SVG), provide a clear and interpretable representation of visual content. Moreover, LLMs have been applied to various programming tasks, such as code retrieval, automated testing, and generation; however, understanding symbolic graphics programs is largely different, as their semantic meaning is often defined visually. Existing benchmarks for LLMs focus on non-graphics program understanding, while vision-language models are evaluated using multimodal datasets for tasks like image captioning and visual question answering.
Researchers from the Max Planck Institute for Intelligent Systems, Tübingen, University of Cambridge, and MIT have proposed a novel approach to evaluate and enhance LLMs’ understanding of symbolic graphics programs. A benchmark called SGP-Bench is introduced for LLMs’ semantic understanding and consistency in interpreting SVG (2D vector graphics) and CAD (2D/3D objects) programs. Moreover, a new fine-tuning method based on a collected instruction-following dataset called symbolic instruction tuning is developed to enhance performance. Also, the symbolic MNIST dataset created by the researchers shows major differences between LLM and human understanding of symbolic graphics programs.
The process of constructing a benchmark to evaluate LLMs’ understanding of symbolic graphics programs uses a scalable and efficient pipeline. It uses a powerful vision-language model (GPT-4o) to generate semantic questions based on rendered images of the symbolic programs. Further, human annotators verify the quality and accuracy of these automatically generated question-answer pairs. This approach reduces the manual effort needed compared to traditional data creation methods. The process for SVG and 2D CAD programs is straightforward as they directly produce 2D images, but in 3D CAD programs, the 3D models are first converted into 2D images from multiple fixed camera positions.
The evaluation of LLMs’ understanding of symbolic graphics programs is done on the SGP-MNIST dataset that consists of 1,000 SVG programs that render MNIST-like digit images, with 100 programs per digit (0-9). While humans can easily recognize the images, LLMs found it extremely challenging to interpret the symbolic programs. Even the advanced GPT-4o model performed only slightly better than random guessing. This stark contrast between human and LLM performance highlights a significant gap in how machines process and understand symbolic representations of visual information compared to humans.
In conclusion, researchers present a new way to evaluate LLMs by assessing their ability to understand images directly from their symbolic graphics programs without visual input. The researchers created the SGP-Bench, a benchmark that effectively measures how well LLMs perform in this task. They also introduced Symbolic Instruction Finetuning (SIT) to enhance LLMs’ ability to interpret graphics programs. This research helps provide a clearer picture of LLM capabilities and promotes the creation of varied evaluation tasks. Future research includes investigating how LLMs understand semantics in this area and working on developing advanced methods to improve their performance in these tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.









