Revisiting Weight Decay: Beyond Regularization in Modern Deep Learning
Weight decay and ℓ2 regularization are crucial in machine learning, especially in limiting network capacity and reducing irrelevant weight components. These techniques align with Occam’s razor principles and are central to discussions on generalization bounds. However, recent studies have questioned the correlation between norm-based measures and generalization in deep networks. Although weight decay is widely used in state-of-the-art deep networks like GPT-3, CLIP, and PALM, its effect is still not fully understood. The emergence of new architectures like transformers and nearly one-epoch language modeling has further complicated the applicability of classical results to modern deep-learning settings.
Efforts to understand and utilize weight decay have significantly progressed over time. Recent studies have highlighted the distinct effects of weight decay and ℓ2 regularization, especially for optimizers like Adam. It also highlights weight decay’s influence on optimization dynamics, including its impact on effective learning rates in scale-invariant networks. Other methods include its role in regularizing the input Jacobian and creating specific dampening effects in certain optimizers. Moreover, a recent investigation contains the relationship between weight decay, training duration, and generalization performance. While weight decay has been shown to improve test accuracy, the improvements are often modest, suggesting that implicit regularization plays a significant role in deep learning.
Researchers from the Theory of Machine Learning Lab at EPFL have proposed a new perspective on the role of weight decay in modern deep learning. Their work challenges the traditional view of weight decay as primarily a regularization technique, as studied in classical learning theory. They have shown that weight decay significantly modifies optimization dynamics in overparameterized and underparameterized networks. Moreover, weight decay prevents sudden loss of divergences in bfloat16 mixed-precision training, a crucial aspect of LLM training. It applies across various architectures, from ResNets to LLMs, indicating that the primary advantage of weight decay lies in its ability to influence training dynamics rather than acting as an explicit regularizer.
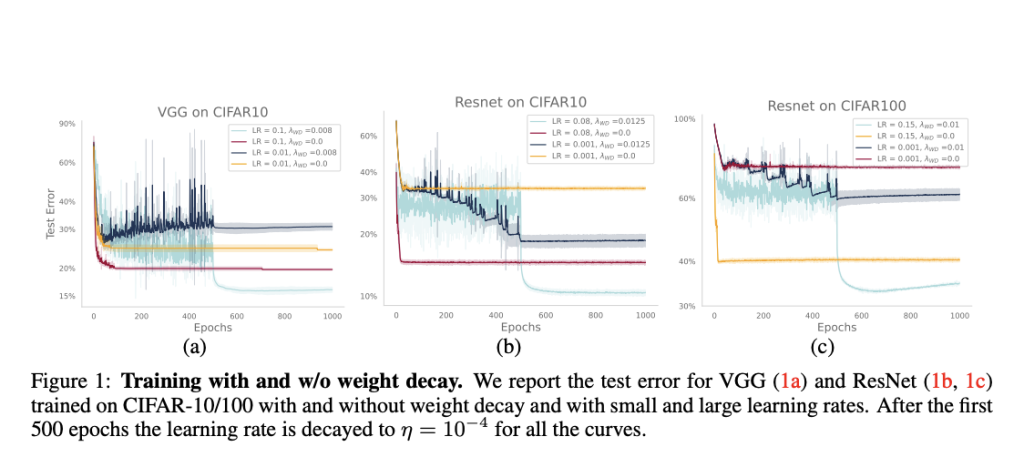
The experiments are carried out by training GPT-2 models on OpenWebText using the NanoGPT repository. A 124M parameter model (GPT-2-Small) trained for 50,000 iterations is used, with modifications to ensure practicality within academic constraints. It is found that training and validation losses remain closely aligned across different weight decay values. The researchers propose two primary mechanisms for weight decay in LLMs:
Improved optimization, as observed in previous studies.
Prevention of loss divergences when using bfloat16 precision.
These findings contrast with data-limited environments where generalization is the key focus, highlighting the importance of optimization speed and training stability in LLM training.
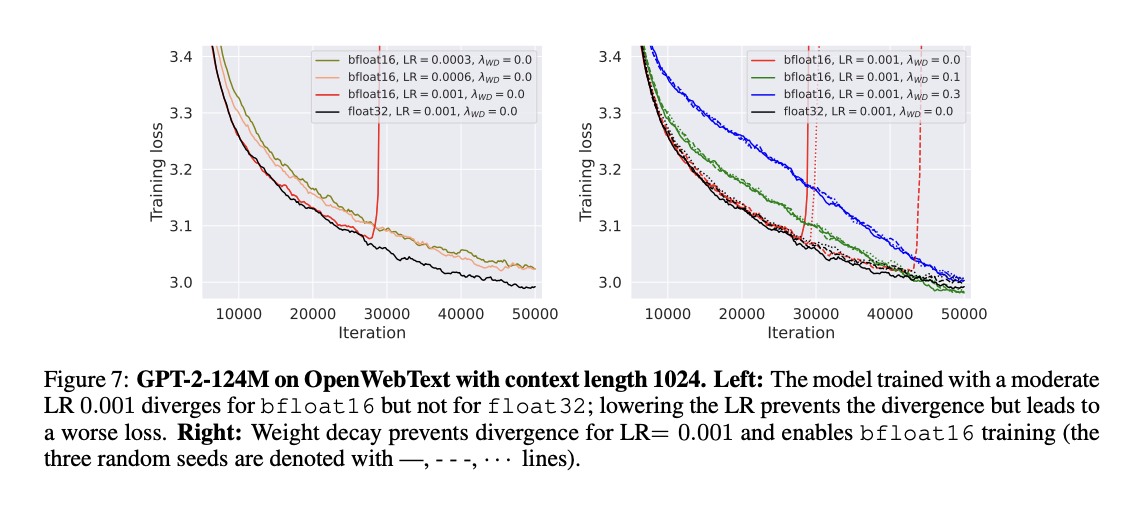
Experimental results reveal a crucial effect of weight decay in enabling stable bfloat16 mixed-precision training for LLMs. Bfloat16 training accelerates the process and reduces GPU memory usage, enabling the training of larger models and bigger batch sizes. However, even the more stable bfloat16 can exhibit late-training spikes that harm model performance. It is also found that weight decay prevents these divergences. While float16 training is known to encounter issues with moderately large values exceeding 65,519, it poses a different challenge, and its limited precision can lead to problems when adding network components with varying scales. Weight decay effectively solves these precision-related issues by preventing excessive weight growth.
In this paper, researchers presented a new perspective on the role of weight decay in modern deep learning. They concluded that weight decay shows three distinct effects in deep learning:
Providing regularization when combined with stochastic noise.
Enhancing optimization of training loss
Ensuring stability in low-precision training.
Researchers are challenging the traditional idea that weight decay primarily acts as an explicit regularizer. Instead, they argue that its widespread use in modern deep learning is due to its capacity to create beneficial changes in optimization dynamics. This viewpoint offers a unified explanation for the success of weight decay across different architectures and training settings, ranging from vision tasks with ResNets to LLMs. Future approaches include model training and hyperparameter tuning in the deep learning field.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit.
We are inviting startups, companies, and research institutions who are working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.