Ready Tensor’s Deep Dive into Time Series Step Classification: Comparative Analysis of 25 Machine Learning and Neural Network Models
Time series analysis is a complex & challenging domain in data science, primarily due to the sequential nature and temporal dependencies inherent in the data. Step classification in this context involves assigning class labels to individual time steps, which is crucial in understanding patterns and making predictions. Ready Tensor conducted an extensive benchmarking study to evaluate the performance of 25 machine learning models on five distinct datasets to improve time series step classification accuracy in their latest publication on Time Step Classification Benchmarking.
The study assessed each model using four primary evaluation metrics, accuracy, precision, recall, and F1-score, across various time series data. The comprehensive analysis highlighted significant variations in model performance, showcasing the strengths and limitations of different modeling approaches. The results indicate that choosing the right model based on the dataset’s characteristics and the classification task is critical for achieving high performance. This publication provides a valuable resource for selecting models and contributes to the ongoing discourse on methodological advancements in time series analysis.
Datasets Overview
The benchmarking study used five distinct datasets chosen to represent a diverse set of time series classification tasks. The datasets included real-world and synthetic data, covering various time frequencies and series lengths. The datasets are briefly described as follows:
HAR70Plus: A dataset derived from the Human Activity Recognition (HAR) dataset, consisting of 18 series with seven classes and six features. The minimum series length is 871, and the maximum is 1536.
HMM Continuous: A synthetic dataset comprising 500 series with four classes and three features, ranging from 50 to 300 time steps.
Multi-Frequency Sinusoidal: Another synthetic dataset with 100 series, five classes, and two features, with a series length ranging from 109 to 499 time steps.
Occupancy Detection: A real-world dataset with only one series, two classes, and five features, consisting of 20,560 time steps.
PAMAP2: A human activity dataset containing nine series, 12 classes, and 31 features, with a series length ranging from 64 to 2725.
The datasets, including HAR70 and PAMAP2, are aggregated versions sourced from the UCI Machine Learning Repository. The data were mean-aggregated to create datasets with fewer time steps, making them suitable for the study.
Evaluated Models
Ready Tensor’s benchmarking study categorized the 25 evaluated models into three main types: Machine Learning (ML) models, Neural Network models, and a special category called the Distance Profile model.
Machine Learning Models: This group includes 17 models selected for their ability to handle sequential dependencies within time series data. Examples of models in this category are Random Forest, K-Nearest Neighbors (KNN), and Logistic Regression.
Neural Network Models: This category comprises seven models and features advanced neural network architectures adept at capturing intricate patterns and long-range dependencies in time series data. Prominent models include Long-Short-Term Memory (LSTM) and Convolutional Neural Networks (CNN).
Distance Profile Model: This model, mentioned in the study, employs a unique approach based on computing distances between time series data points. It stands apart from traditional machine learning and neural network methods and provides a different perspective on time series classification.
Results and Insights
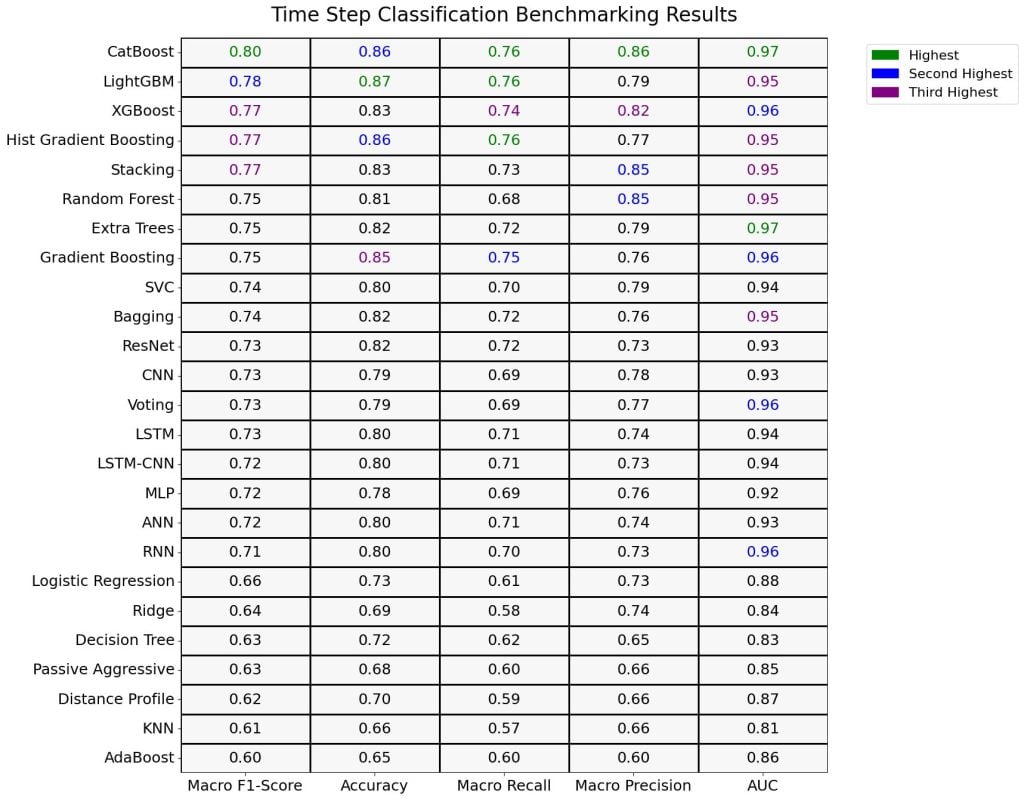
The study evaluated each model individually across all datasets, averaging the performance metrics to derive an overall score. The consolidated data was presented in a heatmap, with models listed on the y-axis and the metrics, accuracy, precision, recall, and F1-score, on the x-axis. The values represented the average of each metric across all datasets, providing a clear visual comparison of model performance.
Top Performers: The results showed that boosting algorithms and advanced ensemble methods performed exceptionally well. CatBoost achieved an F1-score of 0.80, followed by LightGBM at 0.78, Hist Gradient Boosting at 0.77, and XGBoost and Stacking at 0.77. These models excelled in managing complex features and handling imbalanced datasets.
Strong Contenders: Models such as Gradient Boosting and Extra Trees scored 0.75, while Random Forest delivered a solid performance of 0.75. These models proved to be reliable choices, particularly in scenarios where the top performers might be computationally expensive or prone to overfitting.
Baseline or Average Performers: Models like Bagging and SVC scored 0.74, along with neural network models like CNN, RNN, and LSTM at 0.73. These models provided reasonable performance and could serve as baselines for comparison.
Below-average Performers: Models like Logistic Regression (0.66), Ridge (0.64), and Decision Tree (0.63) struggled to capture complex temporal dependencies. KNN and AdaBoost scored at the lower end of the spectrum, with F1 Scores of 0.61 and 0.60, respectively.
Conclusion
The benchmarking study by Ready Tensor offers a detailed evaluation of 25 models across five datasets for time series step classification. The results underscore the effectiveness of boosting algorithms such as CatBoost, LightGBM, and XGBoost in managing time series data. The study’s heatmap visualization provided a comprehensive comparison, highlighting strengths and weaknesses across various modeling approaches. This publication serves as a valuable guide for researchers and practitioners, aiding in selecting appropriate models for time series step classification tasks and contributing to developing more effective and efficient solutions in this evolving field.
Check out the Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.