
Can LLMs Follow Instructions Reliably? A Look at Uncertainty Estimation Challenges
Large Language Models (LLMs) have potential applications in education, healthcare, mental health support, and other domains. However, their accuracy and consistency in following user instructions determine how valuable they are. Even small departures from directions might have serious repercussions in high-stakes situations, such as those involving delicate medical or psychiatric guidance. The ability of LLMs to comprehend and carry out instructions accurately is, therefore, a major problem for their safe deployment.
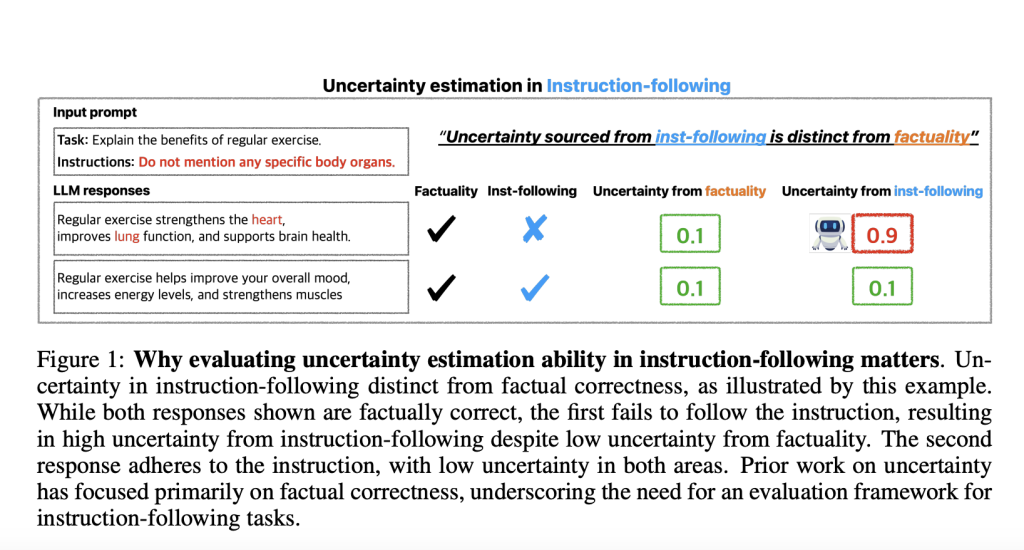
Recent studies have revealed significant limitations in LLMs’ capacity to reliably follow directions, raising questions regarding their dependability in practical situations. Sometimes, even sophisticated models misunderstand instructions or depart from them, which might reduce their effectiveness, particularly in delicate situations. In light of these drawbacks, a trustworthy technique for determining when and how an LLM may be unsure about its capacity to follow directions is necessary to reduce the dangers involved with using these models. An LLM can provide additional human review or protections that can avoid unexpected consequences when it is able to detect high uncertainty in situations where it is uncertain about its reaction.
In a recent study, a team of researchers from the University of Cambridge, the National University of Singapore and Apple shared a thorough assessment of LLMs’ ability to evaluate their uncertainty in instruction-following scenarios precisely. Instruction-following tasks pose distinct difficulties in contrast to fact-based tasks, where uncertainty estimates concentrate on the accuracy of the data. An LLM’s capacity to assess doubt about satisfying certain requirements, such as avoiding certain topics or producing responses in a particular tone, is complicated. It was challenging to determine the LLM’s actual capacity to follow instructions on its own in earlier benchmarks because several elements, such as uncertainty, model correctness, and instruction clarity, were frequently entangled.
The team has developed a systematic evaluation framework in handle these complications. To provide a more transparent comparison of uncertainty estimating techniques under controlled circumstances, this method presents two iterations of a benchmark dataset. While the Realistic benchmark version includes naturally generated LLM responses that mimic real-world unpredictability, the Controlled benchmark version eliminates external influences to offer a clear framework for evaluating the models’ uncertainty.
The results have demonstrated the limitations of the majority of current uncertainty estimating techniques, especially when dealing with modest instruction-following failures. Although techniques that use LLMs’ internal states demonstrate some progress over more straightforward methods, they are still insufficient in complex situations where replies might not precisely match or contradict the instructions. This suggests that LLMs need to improve their uncertainty estimation, particularly for complex instruction-following tasks.
The team has summarized their primary contributions as follows.
This study closes a significant gap in previous research on LLMs by offering the first comprehensive evaluation of the effectiveness of uncertainty estimation techniques in instruction-following tasks.
After identifying issues in the previous datasets, a new benchmark has been created for instruction-following tasks. This benchmark enables a direct and thorough comparison of uncertainty estimating techniques in both controlled and real-world scenarios.
Some techniques, such as self-evaluation and probing, exhibit promise, but they have trouble following more complicated instructions. These results have highlighted how crucial it is to conduct more research to improve uncertainty estimates in tasks involving the following instructions, as this could improve the dependability of AI agents.
In conclusion, these results highlight how crucial it is to create fresh approaches to evaluating uncertainty that are tailored to instruction-following. These developments can increase LLMs’ credibility and allow them to function as trustworthy AI agents in domains where accuracy and security are essential.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.









